

Batch routines are the rule in the financial world to solve use cases that demand settlement processes or due dates. These tasks need to be done within a specific time frame and usually involve massive amounts of data. These routines are generally a chore to take care of and monitor. Nothing guarantees that they will start at the given time. They also have a massive impact on the persistence layer because they try to handle all the data simultaneously, causing performance degradation while running (Think about morning runs). At Pismo, we replaced most of our batch routines with an event-driven model that has many advantages. Let’s take a look at it.
The weaknesses of batch jobs
- Those routine jobs have five problems:
- They are, by definition, a single point of failure.
- Those jobs are hard on the persistence layer.
- They are challenging to maintain.
- They are unfit for canary deployment.
- In case of failure, you will have to rerun the whole process.
They usually follow this pattern:
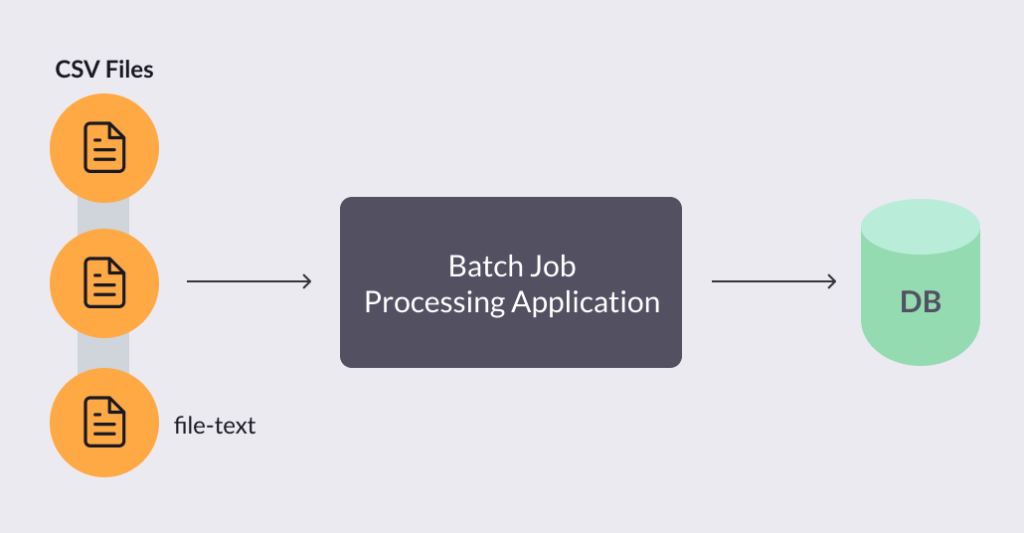
OK, so how can we change that? How can we get by without a scheduled routine job doing the processing that we need in a specific time frame and scale simultaneously? We can do this by using the event-driven model and scheduling techniques!
The event-driven model
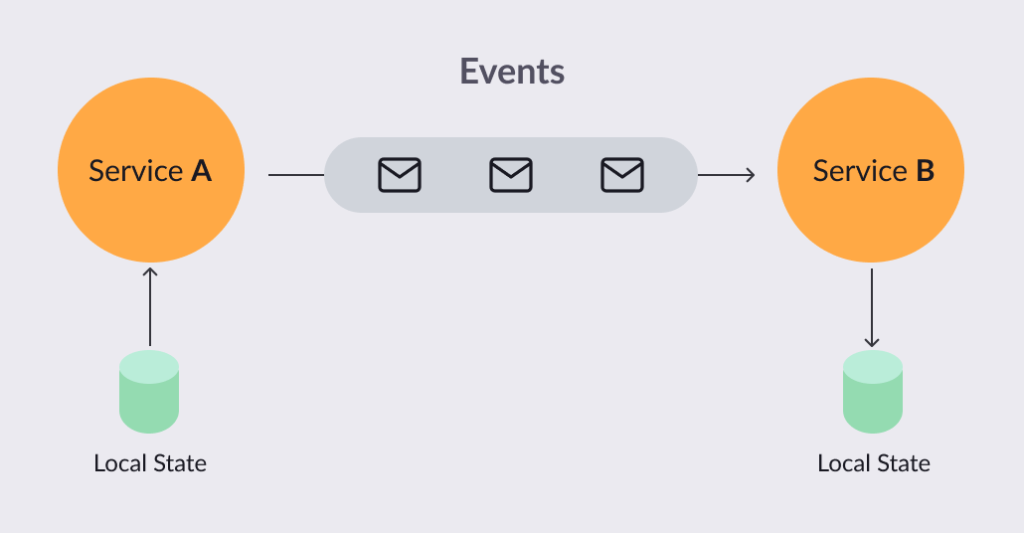
First, to clarify the event-driven model: it’s a form of making two services communicate with each other by passing asynchronous messages through a broker — instead of the traditional RPC calls between your APIs. This form of communication assures that, once a service posts a message to the broker, receivers can receive it multiple times, and they can consume the messages at their own pace.
Some of the critical points of the event-driven model are:
- Interactions are done through messaging.
- The state of the message is persistent.
- Events can be replayed.
- There may be multiple consumers per message.
- A consumer processes the message when they want (pull model).
The scheduling principles
For the scheduling technique, we will have to follow some rules that we will call “The scheduling principles,” which are four:
- There has to be a trigger mechanism.
- The state must be stored.
- It can only affect one domain/user per message.
- The messages must be idempotent.
These principles are necessary to avoid integrity problems. Now let’s take a look at its implementation.
The implementation
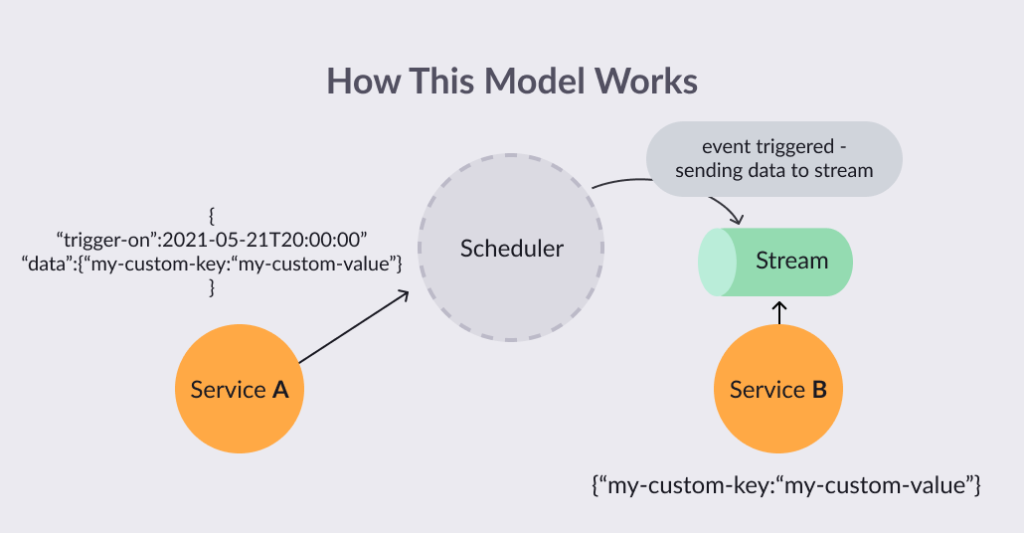
The diagram above shows how we implement this architecture. First, we have service A, which posts a message to the scheduler, responsible for holding it until it’s time to send it to whoever is listening — either through messaging or a stream that will do the business layer processing.
Service A will be responsible for knowing when that message must be processed (an hour later, a day later, or even years later). That is one of the challenging parts of this solution. Service A will need to know what data is required in the message so that service B can process it.
Now let’s consider a critical component here: the scheduler. It can be from any vendor of your choice, even yourself. However, solutions that implement this scheduler and scale for higher volumes are hard to find. Here is a small list: AWS DynamoDB TTL event streams, AWS Step Functions, and Google Cloud scheduler.
The only rule here is that no business logic should be attributed to the scheduler. It should be only responsible for receiving the message, holding it, and then posting it to a queue or stream.
Service B, the last component of this design, will be responsible for actually doing the business logic. It should be capable of handling the same message multiple times (idempotency). It should also process only one user per message to scale horizontally (the more events fired, the more service B will scale to consume them on time). Service B can even “re-schedule” the message to perpetuate this cycle of routine processing (but I will save this for another post).
All the necessary logic to make this asynchronous message flow work should be implemented at service B. Service A and the scheduler should only be the way of sending a message “to the future.” Thus it should not have any custom logic tied to it.
An event-driven application
Now that you know how to implement this strategy to avoid batch jobs, let’s see an example of a feature that follows this model. It is our payment request expiration feature.
Pismo offers a payment request solution. It enables our customers to allow their end-users to request payments from their peers. Imagine, for instance, that you want to ask your friend John to pay you for that 100 dollar restaurant bill from yesterday. With our expiration feature, you can set an expiration date for that request – maybe one week later – so that, once it expires, it triggers another warning.
To do that, traditionally we would create a job that searches for a payment request with a “PENDING” status flag. Then we would process that request according to the business logic.
But we can, instead, follow the scheduling model to avoid that job, like in this diagram:
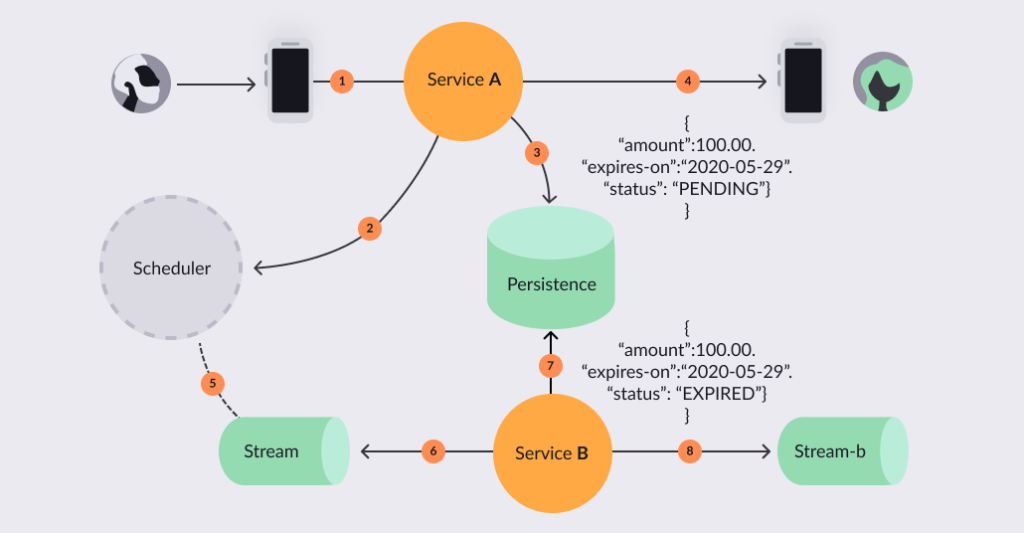
In this scenario, John calls our service A, which will send the message with the necessary data, including the expiration date, to the scheduler system. After it, service A will also store the message in its persistence layer and forward the 100 dollar payment request to John’s friend Doe.
Once the expiration date finally comes, the scheduler system will fire an event with the same data received previously — in a stream that service B is listening to.
Service B will use that stream message to query more information about the domain. Then it will proceed to do the business logic related to the payment request. If successful, it will set the payment request status to “EXPIRED.”
This will conclude the execution of the payment request expiration feature. It will also send another message informing everyone that the payment request is now expired — so we can set up push notifications, warnings, and other actions.
Conclusion
Hopefully, after reading this post, you will start to think about replacing your current routine jobs with this event-driven approach or other variations that come into your mind — as we did here at Pismo. One of the most valuable benefits of this approach is that it allows us to scale our routine jobs horizontally. Additionally, it enables us to do isolated canary deployments in production. So we can initially roll out our new business logic changes only to a specific subset of customers — not to the entire dataset.
Thanks for reading this post. Reach out for any questions or maybe for just a quick chat ([email protected])!
- Learn more by downloading our complimentary whitepaper:
Event-Driven Architecture: the Foundation of Next-Generation Banking








